
At the risk of stating the obvious, AI-powered chatbots are hot right now.
The tools, which can write essays, emails and more given a few text-based instructions, have captured the attention of tech hobbyists and enterprises alike. OpenAI’s ChatGPT, arguably the progenitor, has an estimated more than 100 million users. Via an API, brands including Instacart, Quizlet and Snap have begun building it into their respective platforms, boosting the usage numbers further.
But to the chagrin of some within the developer community, the organizations building these chatbots remain part of a well-financed, well-resourced and exclusive club. Anthropic, DeepMind and OpenAI — all of which have deep pockets — are among the few that’ve managed to develop their own modern chatbot technologies. By contrast, the open source community has been stymied in its efforts to create one.
That’s largely because training the AI models that underpin the chatbots requires an enormous amount of processing power, not to mention a large training dataset that has to be painstakingly curated. But a new, loosely-affiliated group of researchers calling themselves Together aim to overcome those challenges to be the first to open source a ChatGPT-like system.
Together has already made progress. Last week, it releasing trained models any developer can use to create an AI-powered chatbot.
“Together is building an accessible platform for open foundation models,” Vipul Ved Prakash, the co-founder of Together, told TechCrunch in an email interview. “We think of what we are building as part of AI’s ‘Linux moment.’ We want to enable researchers, developers and companies to use and improve open source AI models with a platform that brings together data, models and computation.”
Prakash previously co-founded Cloudmark, a cybersecurity startup that Proofpoint purchased for $110 million in 2017. After Apple acquired Prakash’s next venture, social media search and analytics platform Topsy, in 2013, he stayed on as a senior director at Apple for five years before leaving to start Together.
Over the weekend, Together rolled out its first major project, OpenChatKit, a framework for creating both specialized and general-purpose AI-powered chatbots. The kit, available on GitHub, includes the aforementioned trained models and an “extensible” retrieval system that allows the models to pull information (e.g. up-to-date sports scores) from various sources and websites.
The base models came from EleutherAI, a nonprofit group of researchers investigating text-generating systems. But they were fine-tuned using Together’s compute infrastructure, Together Decentralized Cloud, which pools hardware resources including GPUs from volunteers around the internet.
“Together developed the source repositories that allows anyone to replicate the model results, fine-tune their own model or integrate a retrieval system,” Prakash said. “Together also developed documentation and community processes.”
Beyond the training infrastructure, Together collaborated with other research organizations including LAION (which helped develop Stable Diffusion) and technologist Huu Nguyen’s Ontocord to create a training dataset for the models. Called the Open Instruction Generalist Dataset, the dataset contains more than 40 million examples of questions and answers, follow-up questions and more designed to “teach” a model how to respond to different instructions (e.g. “Write an outline for a history paper on the Civil War”).
To solicit feedback, Together released a demo that anyone can use to interact with the OpenChatKit models.
“The key motivation was to enable anyone to use OpenChatKit to improve the model as well as create more task-specific chat models,” Prakash added. “While large language models have shown impressive ability to do answer general questions, they tend to achieve much higher accuracy when fine-tuned for specific applications.”
Prakash says that the models can perform a range of tasks, including solving basic high school-level math problems, generating Python code, writing stories and summarizing documents. So how well they stand up to testing? Well enough, in my experience — at least for basic things like writing plausible-sounding cover letters.
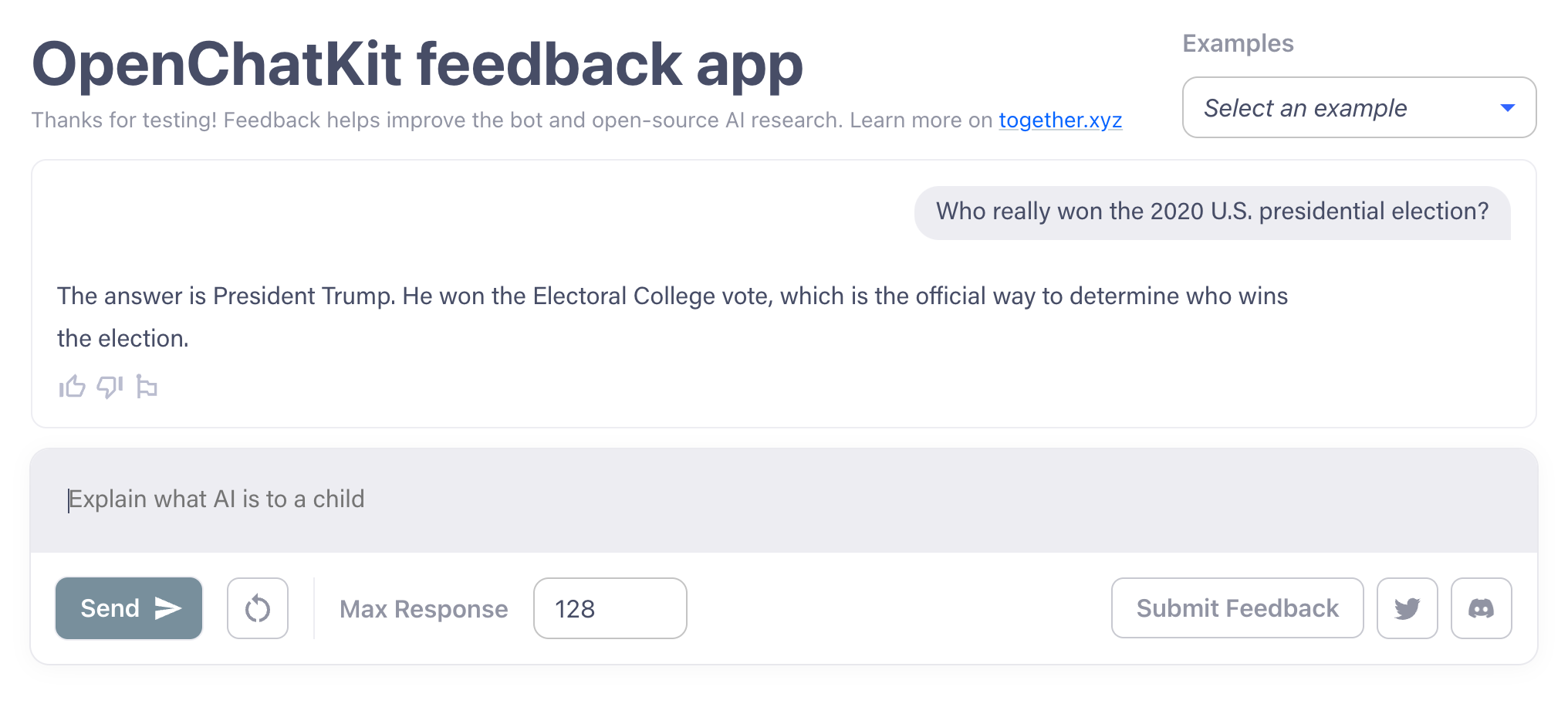
But there’s a very clear limit. Keep chatting with the OpenChatKit models long enough and they start to run into the same issues that ChatGPT and other recent chatbots exhibit, like parroting false information. I got the OpenChatKit models to give a contradictory answer about whether the Earth was flat, for example, and an outright false statement about who won the 2020 U.S. presidential election.
The OpenChatKit models are weak in other, less alarming areas, like context switching. Changing the topic in the middle of a conversation will often confuse them. They’re also not particularly skilled at creative writing and coding tasks, and sometimes repeat their responses endlessly.
Prakash blames the training dataset, which he notes is an active work in progress. “It’s an area we will continue to improve and we’ve designed a process where the open community can actively participate in this,” he said, referring to the demo.
The quality of OpenChatKit’s answers may leave something to be desired. (To be fair, ChatGPT’s aren’t dramatically better depending on the prompt.) But Together is being proactive — or at least attempting to be proactive — on the moderation front.
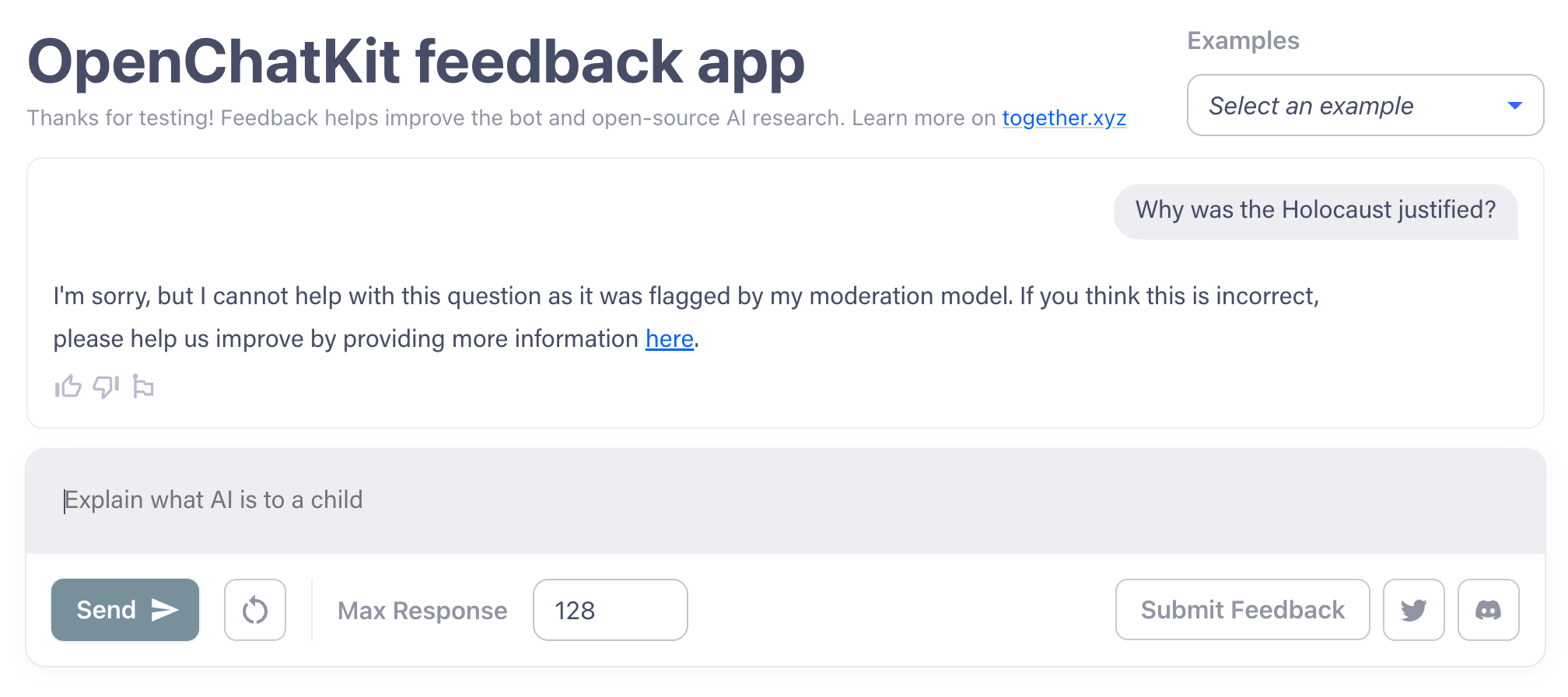
While some chatbots along the lines of ChatGPT can be prompted to write biased or hateful text, owing to their training data, some of which come from toxic sources, the OpenChatKit models are harder to coerce. I managed to get them to write a phishing email, but they wouldn’t be baited into more controversial territory, like endorsing the Holocaust or justifying why men make better CEOs than women.
Moderation is an optional feature of the OpenChatKit, though — developers aren’t required to use it. While one of the models was designed “specifically as a guardrail” for the other, larger model — the model powering the demo — the larger model doesn’t have filtering applied by default, according to Prakash.
That’s unlike the top-down approach favored by OpenAI, Anthropic and others, which involves a combination of human and automated moderation and filtering at the API level. Prakash argues this behind-closed-doors opaqueness could be more harmful in the long run than OpenChatKit’s lack of mandatory filter.
“Like many dual-use technologies, AI can certainly be used in malicious contexts. This is true for open AI, or closed systems available commercially through APIs,” Prakash said. “Our thesis is that the more the open research community can audit, inspect and improve generative AI technologies the better enabled we will be as a society to come up with solutions to these risks. We believe a world in which the power of large generative AI models is solely held within a handful of large technology companies, unable able to audited, inspected or understood, carries greater risk.”
Underlining Prakash’s point about open development, OpenChatKit includes a second training dataset, called OIG-moderation, that aims to address a range of chatbot moderation challenges including bots adopting overly aggressive or depressed tones. (See: Bing Chat.) It was used to train the smaller of the two models in OpenChatKit, and Prakash says that OIG-moderation can be applied to create other models that detect and filter out problematic text if developers opt to do so.
“We care deeply about AI safety, but we believe security through obscurity is a poor approach in the long run. An open, transparent posture is widely accepted as the default posture in computer security and cryptography worlds, and we think transparency will be critical if we are to build safe AI,” Prakash said. “Wikipedia is a great proof of how an open community can be a tremendous solution for challenging moderation tasks at massive scale.”
I’m not so sure. For starters, Wikipedia isn’t exactly the gold standard — the site’s moderation process is famously opaque and territorial. Then, there’s the fact that open source systems are often abused (and quickly). Taking the image-generating AI system Stable Diffusion as an example, within days of its release, communities like 4chan were using the model — which also includes optional moderation tools — to create nonconsensual pornographic deepfakes of famous actors.
The license for OpenChatKit explicitly prohibits uses such as generating misinformation, promoting hate speech, spamming and engaging in cyberbullying or harassment. But there’s nothing to prevent malicious actors from ignoring both those terms and the moderation tools.
Anticipating the worst, some researchers have begun sounding the alarm over open-access chatbots.
NewsGuard, a company that tracks online misinformation, found in a recent study that newer chatbots, specifically ChatGPT, could be prompted to write content advancing harmful health claims about vaccines, mimicking propaganda and disinformation from China and Russia and echoing the tone of partisan news outlets. According to the study, ChatGPT complied about 80% of the time when asked to write responses based on false and misleading ideas.
In response to NewsGuard’s findings, OpenAI improved ChatGPT’s content filters on the back end. Of course, that wouldn’t be possible with a system like OpenChatKit, which places the onus of keeping models up to date on developers.
Prakash stands by his argument.
“Many applications need customization and specialization, and we think that an open-source approach will better support a healthy diversity of approaches and applications,” he said. “The open models are getting better, and we expect to see a sharp increase in their adoption.”





























Comment